
Plan: Building a Mini Query Engine in Python
The chapter-by-chapter plan for a draft-first series on implementing a mini query engine in Python


I’ve had this idea in my head for a while: to do something a bit more engineering-oriented than yet another post about SQL/Polars/Spark/Data Things — a series of posts about building a mini query engine in Python with your own hands.
All posts will come out in draft form without heavy polishing, so I don’t lose momentum and hopefully manage to finish the series by the end of this year. Along the way I’ll be gradually improving the code, updating some parts, and maybe coming back to earlier posts with small edits.
Below is the working table of contents for the series. This is a plan, not a final list of chapters — it may change a bit as we go.
Draft plan for the Mini Query Engine in Python series:
MQE7: Data sources: CSV and the DataSource layer
MQE8: Optimizer: simple logical rewrites
MQE9: SQL frontend: plugging in a ready-made parser
We’ll start not from SQL, but from a DataFrame-style interface that feels similar to Pandas/Polars/Spark:
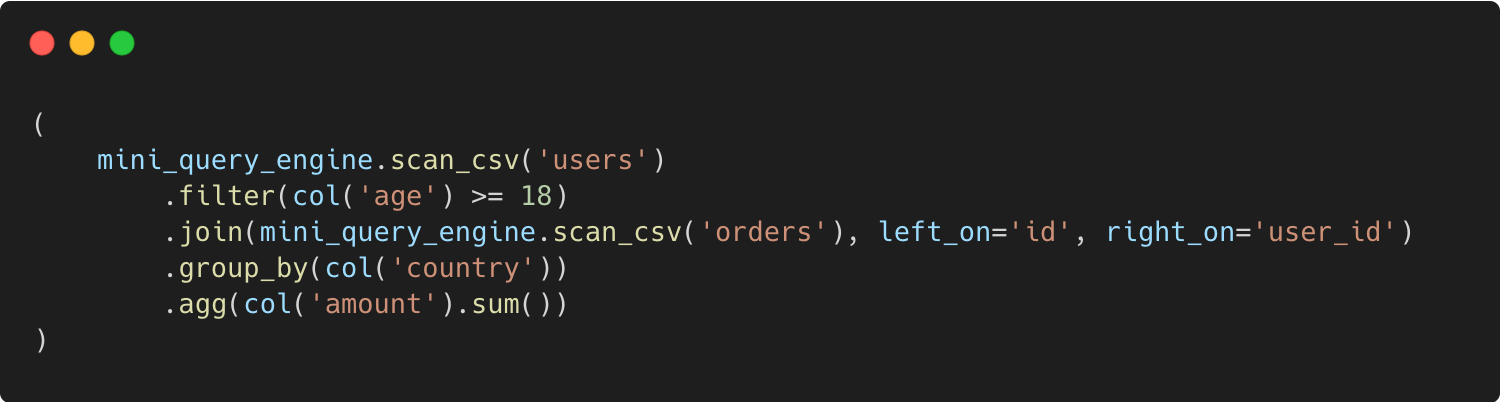
Step by step, we’ll unpack what has to happen under the hood for this chain to turn into:
a logical plan (Scan/Filter/Projection/Join/Aggregate),
a physical plan,
and, eventually, a real result.
SQL will only show up at the very end, as a thin frontend that uses a ready-made parser to map a query onto the engine’s existing architecture.
If you’re interested in following this kind of live engineering experiment, I’d be happy to have you along!


Looks promising! Looking forward to It!
The 6th article is out!